Privacy-first Local Large Language Model.
Simple inference and fine-tuning. No AI expertise needed.
Download nowPrivacy-first.
Your data and models only exist locally and are never uploaded.
Performant.
Up to 100 tokens / second on one RTX 4090.
Chat.
Have conversations with the AI without anyone snooping.
Code completions.
Code quicker with the Neuryte Visual Studio Code plugin.
Simple fine-tuning.
Fine-tune code completions on your own repository, or a custom chat model.
Add documents.
Documents enhance the AI models with new information.
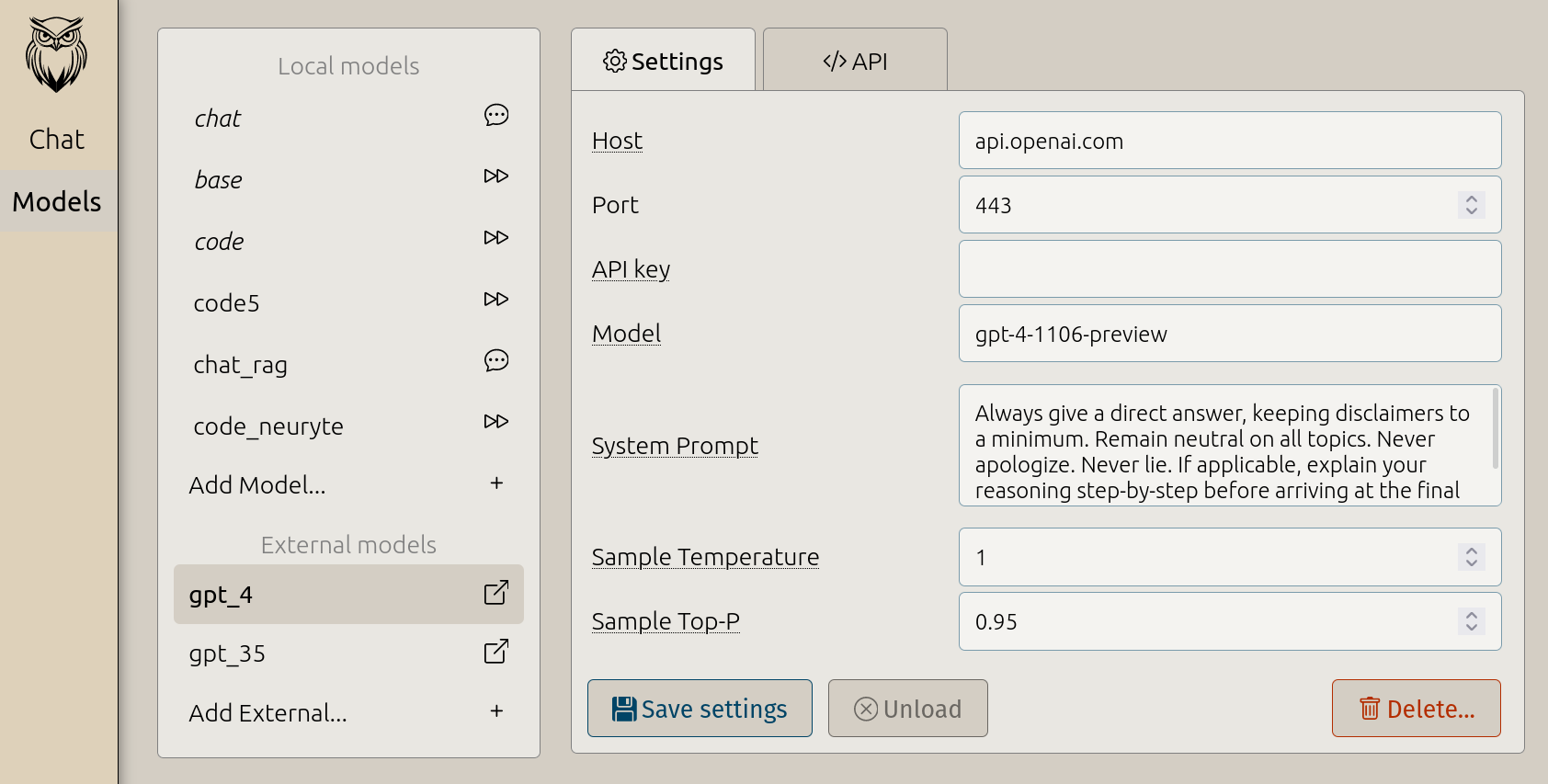
Data Privacy Guaranteed.
Experience full local execution on your own graphics card, ensuring your data's privacy and security. Neuryte LLLM is designed with a strict no-server policy, meaning no chat messages, models, or usage data are ever uploaded externally. This approach guarantees that your information stays private and under your direct control.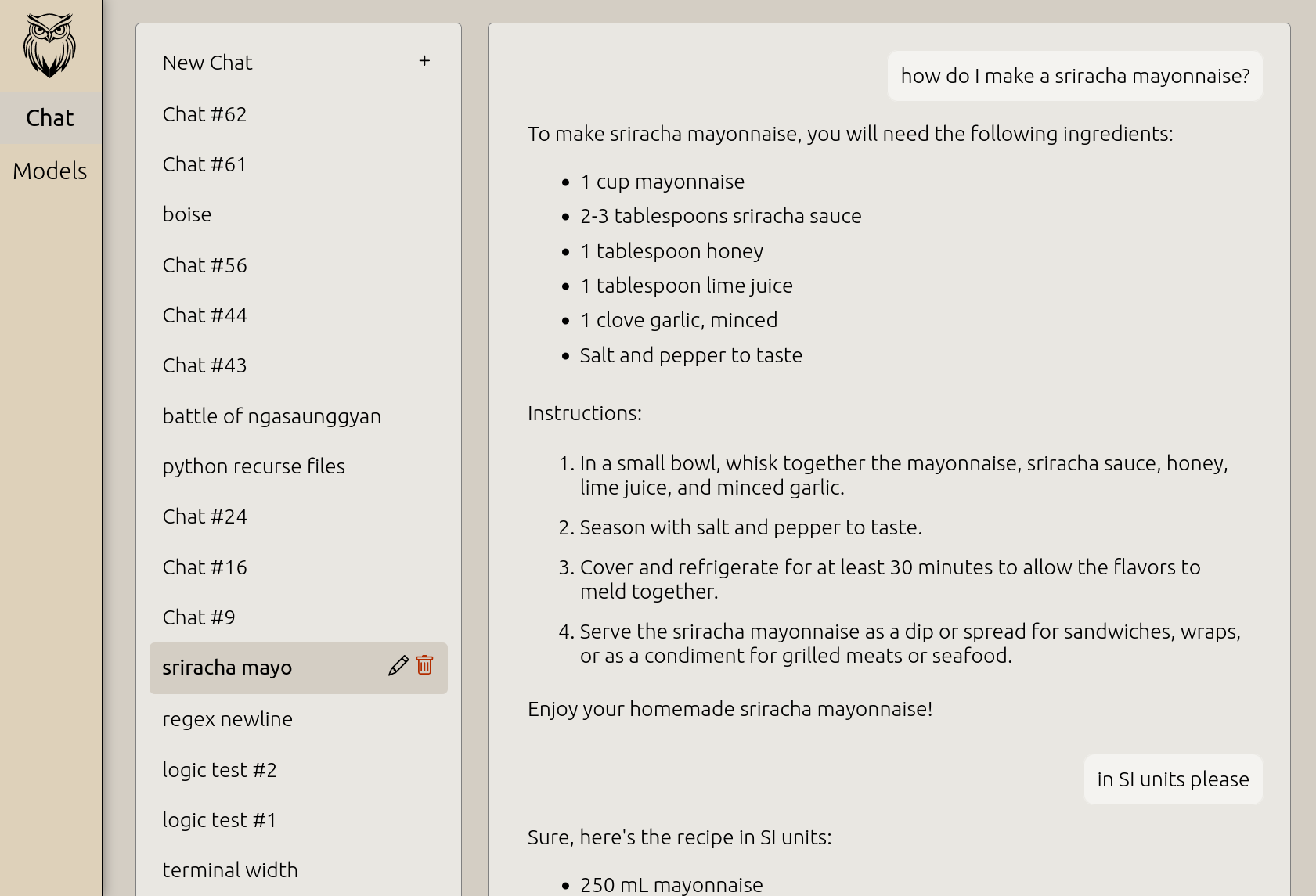
Efficient Local Chat Processing.
Our technology enables fast and local chat processing, ensuring that your conversations remain private while offering quick response times. This setup is ideal for users who prioritize both speed and data security.Enhanced Coding Assistance.
Our integration with Visual Studio Code offers on-demand code suggestions and assistance. The basic code completion model is designed to streamline your coding process, helping you complete lines of code or develop entire functions automatically.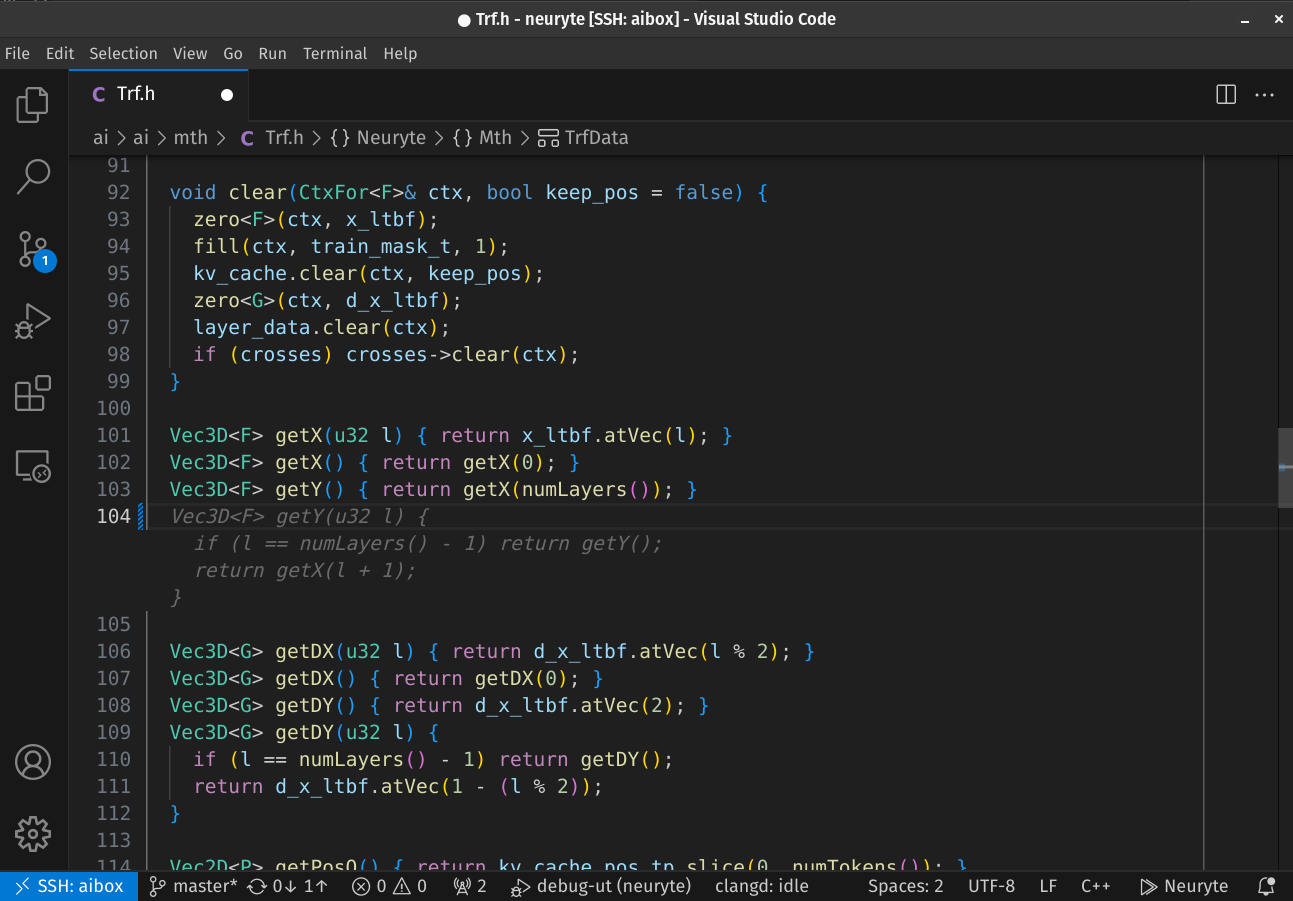
Optimized Performance.
Neuryte LLLM is built for speed, balancing quick response times with useful outputs using the class-leading Mistral 7B foundation model. Utilizing our CUDA-based transformer engine, it achieves low latency and efficient memory usage. Performance metrics for RTX 4090 include inference at 100 tokens/sec for the base model and 80 tokens/sec for fine-tuned models.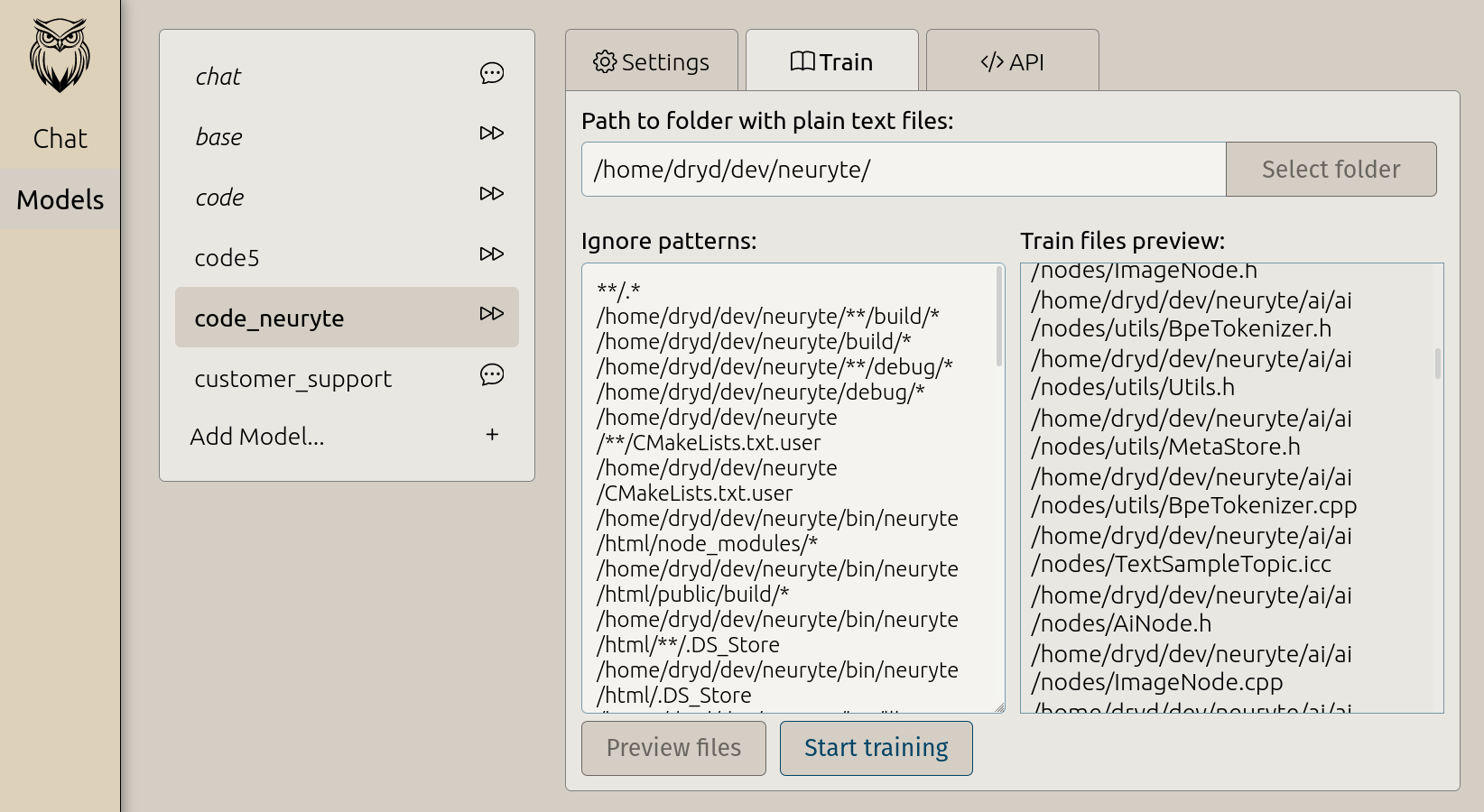
Customizable AI Models.
Users can start with basic chat and code models and tailor them according to their needs using our web-based fine-tuning GUI. As always the data never leaves your computer. Highlights include- Fine-tune models on personal code repositories.
- Fine-tune chat models.
- Self-contained model files. Shared easily, or kept private.
- Less than 8GB GPU memory required.
- Adding information to a model is better done by adding documents.
API Integration for Easy Access.
All models are accessible via an API similar to well-known industry APIs, ensuring ease of use and familiarity for users. This feature enables seamless model loading into memory on-demand, facilitating a smooth workflow and consistent access to AI capabilities for various applications.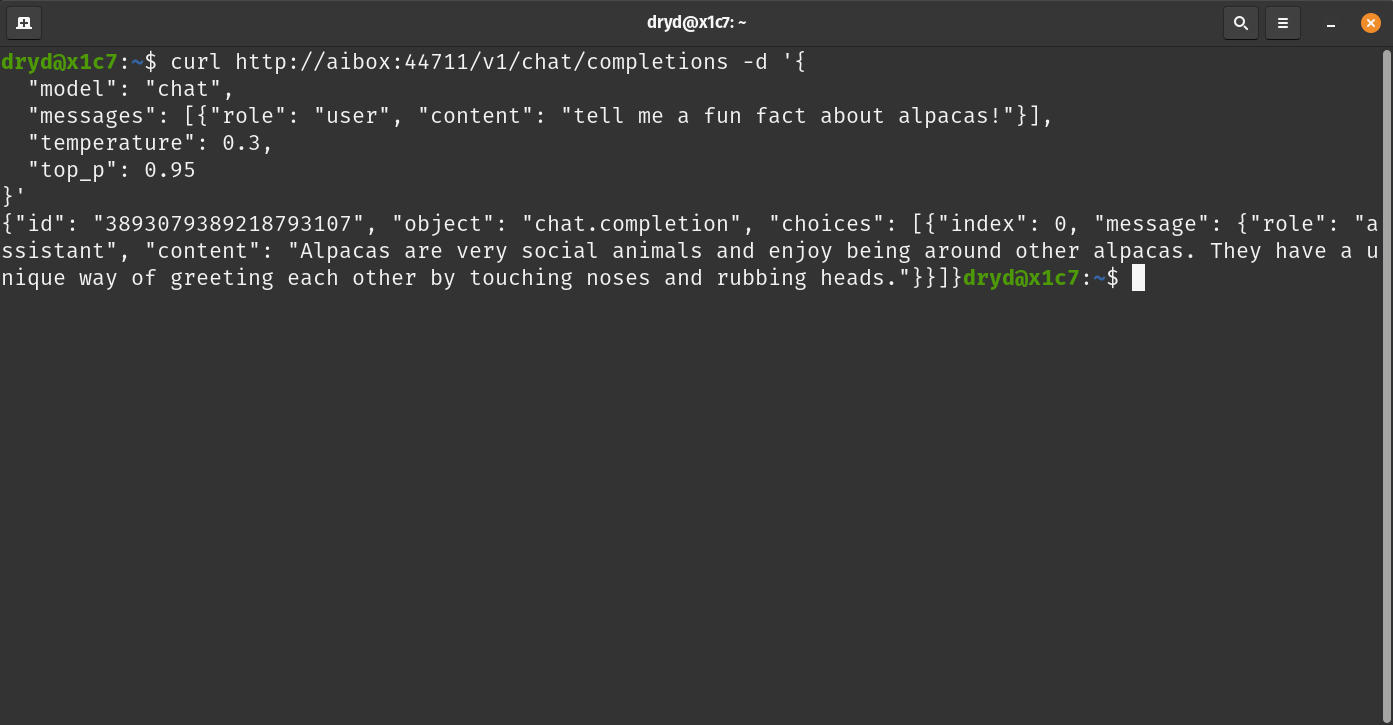
Add documents to your models.
New in v0.2!
Documents can be added to your chat models, and the AI will use them as context to find information, also known as Retrieval Augmented Generation (RAG). - Chat with your own reference information, without needing to upload anything to the internet.
- Reduces hallucinations.
- Most efficient way of adding facts to a model.
- Context easily viewed in the GUI (see screenshot).
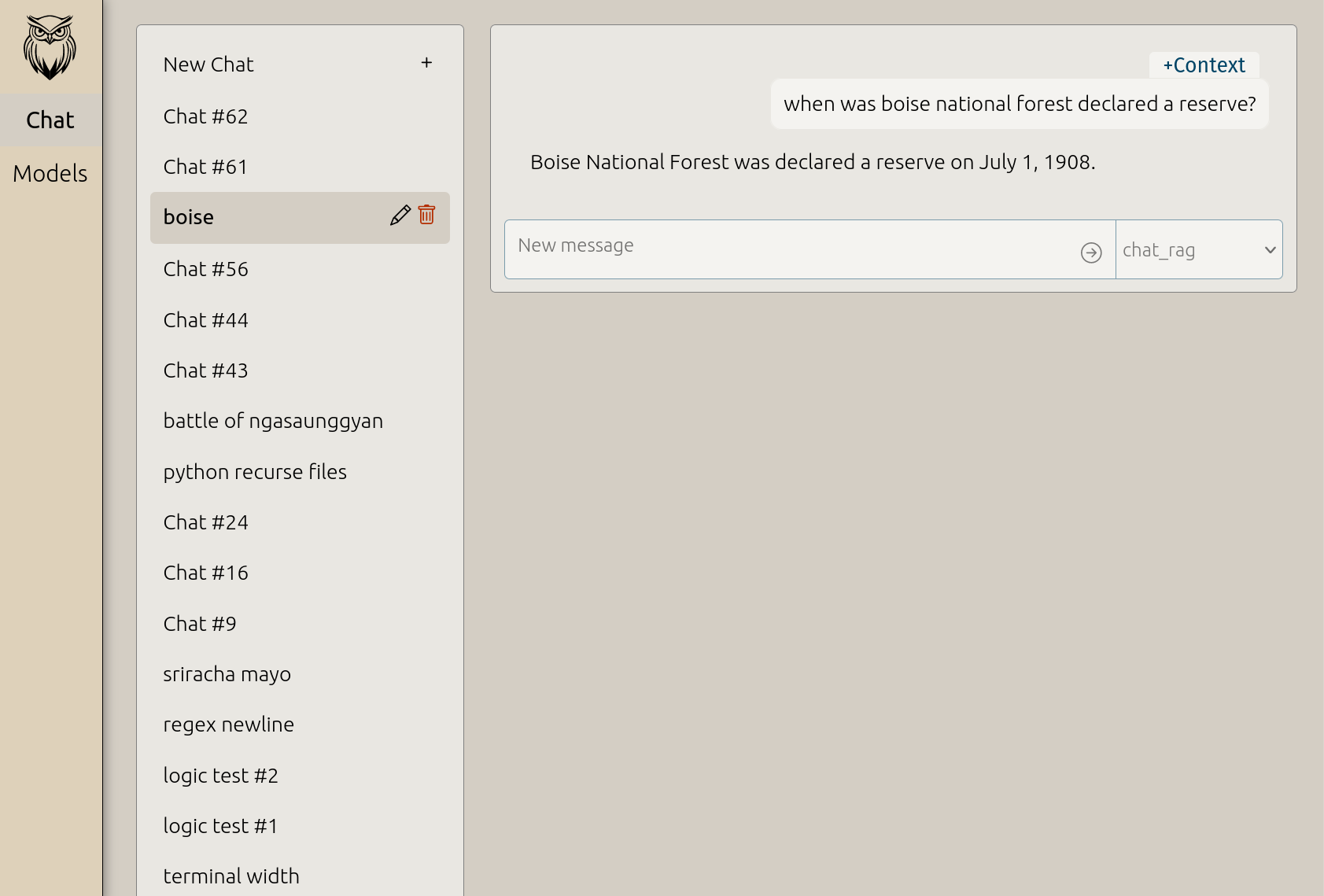
Hover to see the context used by the AI
Chat with external providers.
New in v0.2!
Use the Neuryte LLLM GUI to connect with external AI model providers, for more demanding tasks. - Allows you to pay the provider for usage instead of a monthly fee.
- Requires your own API-key.
- Your chat history is saved locally along with your Neuryte chats.